

AI, cloud computing, and intelligent edge devices are redefining how we design compute systems. Terms like CPU, GPU, TPU, and NPU are now central to discussions around model training, inference efficiency, and system performance.
While all four process data, they are optimized for different workloads. This guide clarifies their architectural differences, performance focus, and practical applications in modern AI systems.
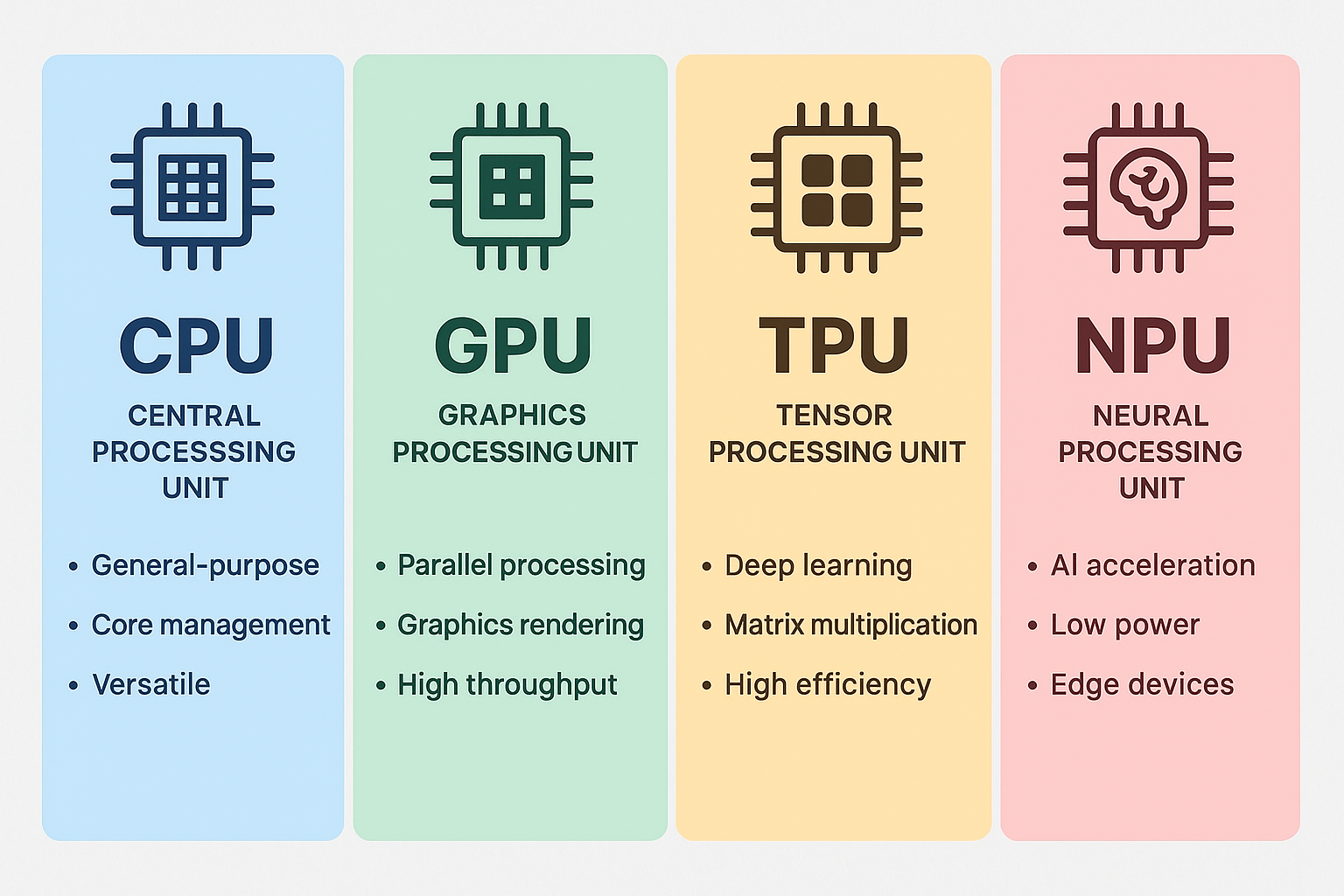
★ What Is a CPU? (Central Processing Unit)
General-Purpose Control and Computation
The CPU is the foundational general-purpose processor in computing systems. It emphasizes low-latency execution, complex branching logic, and system orchestration.
Key characteristics
Multi-stage pipeline and branch prediction
Large cache hierarchy
Optimized for sequential and mixed workloads
Handles operating systems, I/O, scheduling, and general application logic
Ideal for
System orchestration and OS tasks
Database operations and API logic
Pre-/post-processing for AI models
Networking stack and control plane
Limitations
Lower parallel throughput vs GPUs and accelerators
Higher cost per AI operation
★ What Is a GPU? (Graphics Processing Unit)
High-Parallel Compute for ML Training
Originally built for graphics, GPUs excel at massively parallel floating-point operations, making them dominant in deep-learning training.
Key characteristics
Thousands of SIMD/SIMT ALUs
High FP16/FP32 throughput
Extremely efficient at matrix and tensor workloads
Best for
Deep-learning model training
Rendering, simulation, video acceleration
Limitations
High power consumption
Less efficient for non-parallel logic
Requires optimized frameworks and kernels
★ What Is a TPU? (Tensor Processing Unit)
Google’s AI-Dedicated Accelerator
A TPU (Tensor Processing Unit) is a domain-specific AI ASIC developed by Google for matrix multiplication and tensor operations, heavily used in large-scale ML training and inference.
Key architecture traits
Systolic array compute units
High-bandwidth on-chip memory
Optimized for TensorFlow and large transformer models
Best for
Cloud-scale AI and LLM training
High-throughput inference
Recommendation systems, speech, and vision models
Limitations
Primarily available through Google Cloud
Less flexible than GPUs for non-AI tasks
★ What Is an NPU? (Neural Processing Unit)
Efficient On-Device AI Inference
An NPU accelerates deep-learning inference in low-power, edge environments. It is now standard in mobile SoCs, automotive AI chips, and industrial IoT processors.
Key characteristics
Dedicated neural execution pipelines
Quantized compute support (INT8/INT4)
High performance-per-watt for AI workloads
Best for
Mobile AI (vision, speech, AR/VR)
Smart cameras and robotics
Automotive ADAS compute
Local LLM and edge inference
Limitations
Not suitable for large-scale training
Narrower workload flexibility vs CPU/GPU
★ Comparison Table: CPU vs GPU vs TPU vs NPU
Feature | CPU | GPU | TPU | NPU |
|---|---|---|---|---|
Core Focus | Control & logic | Parallel compute | Tensor compute | Edge inference |
Compute Style | Serial + mixed parallel | Massive parallel | Matrix systolic array | Neural pipelines |
Strength | Flexibility | Training & HPC | Large-scale AI | Low-power AI |
Best Location | Servers, PCs | Workstations, cloud | Google Cloud | Edge devices |
★ Real-World Deployment Scenarios
Data Centers
GPU / TPU for training large neural networks
CPU for control plane, scheduling, and I/O
Edge & Embedded
NPU for real-time inference
CPU manages OS, system tasks, and fallback compute
Hybrid AI Strategy
Modern compute stacks increasingly combine CPU + GPU/TPU + NPU to optimize cost, latency, and power efficiency.
★ Connectivity & Hardware Infrastructure
High-performance compute platforms require robust networking and I/O. Reliable physical interfaces ensure data integrity between servers, accelerators, and edge devices.
Related hardware from LINK-PP
High-speed RJ45 Connectors (1G/2.5G/10G, PoE)
Ethernet magnetics & LAN transformers
SFP/QSFP optical transceiver modules for AI cluster networking
Industrial-grade embedded Ethernet components for edge AI gateways
These components support high-bandwidth, low-latency data movement — critical for distributed AI systems.
★ Conclusion
Processor | Primary Role | Best Use |
|---|---|---|
General-purpose compute | System control, mixed compute | |
Parallel compute engine | AI training, HPC workloads | |
Tensor accelerator | Cloud LLM & deep-learning compute | |
Edge-AI inference | Mobile, embedded, automotive AI |
As AI systems scale across cloud, edge, and embedded devices, the future lies in hybrid compute architectures where each processor type operates in its optimal domain.



