

⚙️ What Is a TPU (Tensor Processing Unit)?
A Tensor Processing Unit (TPU) is a custom-designed AI accelerator developed by Google to speed up machine-learning workloads—especially deep-learning operations built on large tensor and matrix computations. Unlike CPUs or GPUs, TPUs are specialised ASICs engineered for high-throughput, high-efficiency neural-network training and inference at scale.
⚙️ Why Google Built the TPU
Optimised for Deep Learning
Neural networks require massive parallel math operations, mainly matrix multiply-accumulate tasks. CPUs struggle with these workloads, while GPUs, although powerful, are general-purpose accelerators.
TPUs were created to:
Deliver extremely high performance per watt
Maximise matrix-multiplication throughput
Support large-scale AI models cost-effectively
Meet rising internal demand across Google Search, Translate, YouTube, Maps, and AI models
AI-First Design
From the beginning, the TPU architecture focused on:
Hardware-software co-design with TensorFlow
Reduced precision formats (e.g. bfloat16, int8) for energy-efficient compute
Scalable fabrics for multi-chip clustering
⚙️ TPU Architecture Explained
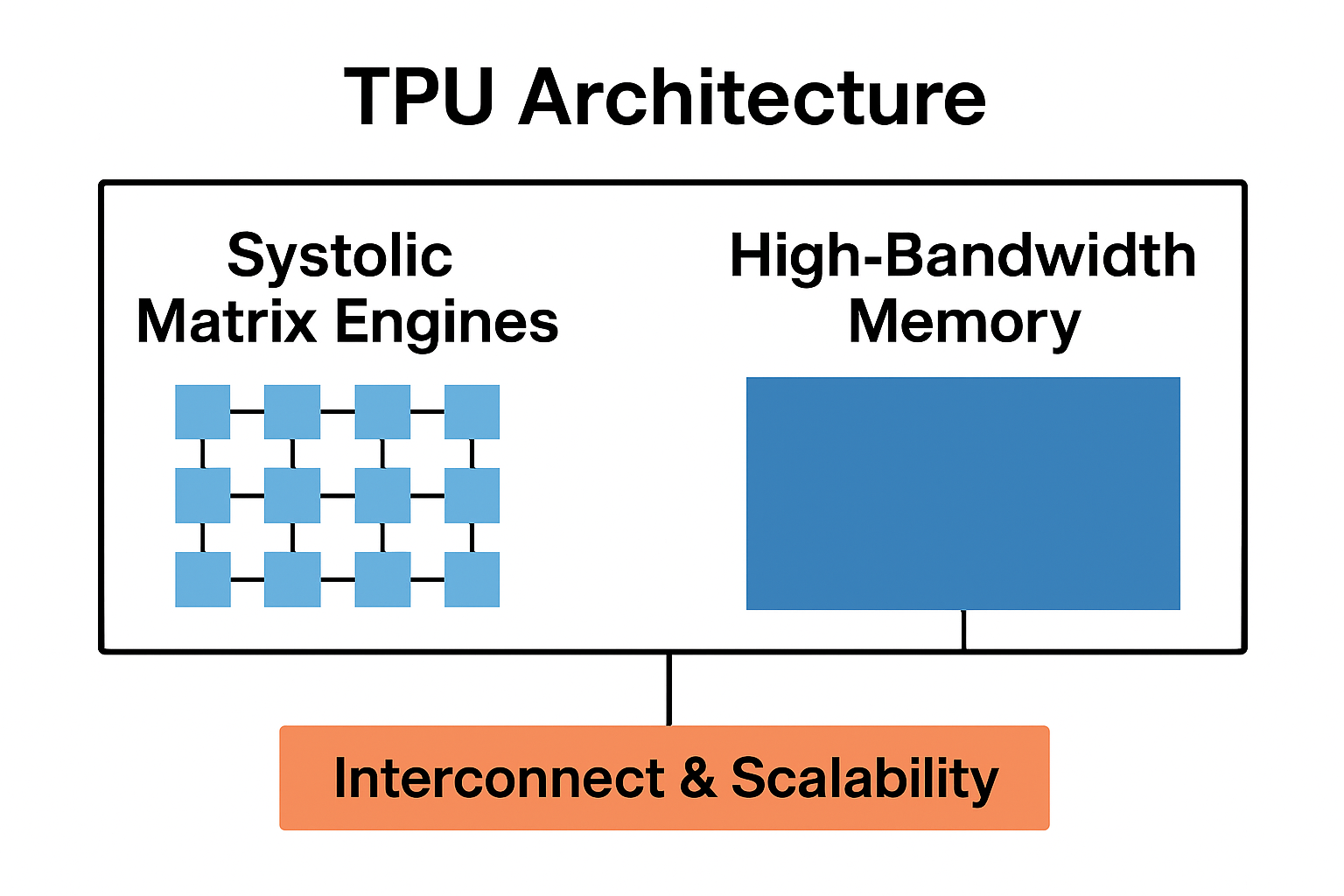
Systolic Matrix Engines
At the core of each TPU chip is a massive matrix multiplication unit arranged in a systolic array, enabling thousands of simultaneous multiply-accumulate operations.
High-Bandwidth Memory
Modern TPUs integrate HBM to feed data at extremely high bandwidth, preventing memory bottlenecks common in GPU-based systems.
Interconnect & Scalability
Individual TPUs scale into TPU Pods, interconnected with low-latency, high-bandwidth networks for multi-exaflop modular AI clusters.
This architecture enables extremely large model training and faster inference at hyperscale.
⚙️ TPU Generations and Key Specs
Generation | Focus | Memory & Compute | Notes |
|---|---|---|---|
TPU v1 | Inference | 8-bit compute | First internal deployment |
TPU v2 | Training & Inference | bfloat16, HBM | Cloud TPU launched |
TPU v3 | Large-scale training | Liquid cooling, HBM | Pod up to ~1K chips |
TPU v4 | Efficient exascale pods | 32GB HBM, advanced mesh | Data-center scale |
TPU v6 “Trillium” | High-density AI compute | Multiple HBM stacks | ~5× perf vs prior |
TPU v7 “Ironwood” | Inference-first architecture | FP8 optimisation | Built for LLM serving |
⚙️ TPU vs GPU vs CPU
Feature | TPU | ||
|---|---|---|---|
Purpose | AI-specific tensor compute | Graphics + ML acceleration | General compute |
Best For | Neural networks, LLMs | HPC, ML, graphics | OS, logic, apps |
Parallelism | Extremely high | High | Low |
Efficiency | Highest for AI workloads | High | General purpose |
Deployment | Cloud & clusters | Cloud & on-prem | Everywhere |
In short:
CPUs are universal. GPUs are versatile. TPUs are laser-focused on AI at scale.
⚙️ Where TPUs Are Used
Large-Scale Model Training
Ideal for transformer models, recommendation systems, and large-language-model training pipelines.
Cloud Inference
TPUs power global AI workloads such as search ranking, language translation, speech recognition, and generative AI services.
Edge TPU
A lightweight TPU variant runs ML inference locally in edge/embedded devices for low-latency AI and power-efficient IoT intelligence.
⚙️ Best Practices for TPU Deployment
Use supported data types (bfloat16 / int8) for maximum efficiency
Optimise data pipelines for distributed compute
Choose TPU Pods for LLM-scale workloads
Consider thermal and network design for cluster scalability
Leverage hybrid cloud + edge strategies for balanced compute density
⚙️ TPUs and the Future of AI Infrastructure
AI models are more compute-intensive than ever, shifting focus from pure training to real-time inference at scale.
TPUs will continue advancing in:
Interconnect density
Energy-efficient architectures
Hybrid precision (e.g., FP8)
Integration with software frameworks (TensorFlow, JAX, PyTorch via XLA)
As AI workloads accelerate, specialised compute and ultra-high-speed connectivity become essential components of modern data-centre and network design.
⚙️ How This Relates to LINK-PP
AI acceleration at hyperscale depends on advanced networking and robust connectivity infrastructure. LINK-PP components support the data-center environment that powers TPU deployments, including:
High-speed RJ45 MagJacks
SFP/25G/100G optical modules
PoE solutions for edge-AI devices
Industrial Ethernet & IoT connectors
⚙️ Conclusion
TPUs represent a major leap in specialised AI computing—purpose-built for tensor workloads and large-scale neural-network operations. As generative AI and deep-learning adoption accelerate globally, TPUs play a crucial role in powering training clusters and inference infrastructure.
For industries building or supporting modern data-centre environments, understanding TPU technology provides valuable insight into the demands of high-performance AI systems—and opportunities in next-generation networking hardware and components.



