
















🔍 Introduction: The Silent Threat of Undetected Failures
In high-performance digital environments, the only thing worse than a system failure is a system failure you don’t know about. These “silent failures” cause damage and degrade service quality long before human operators are alerted, turning minutes into catastrophic hours of downtime.
This is why Mean Time to Detect (MTTD) is the foundational metric of modern reliability engineering. MTTD is the ultimate measure of your monitoring system’s vigilance. By focusing on reducing MTTD, organizations can transform their incident response from a reactive scramble to a proactive, immediate intervention, safeguarding uptime and protecting the customer experience.
🕰️ Defining Mean Time to Detect (MTTD)
MTTD stands for Mean Time to Detect. It is the average duration that passes from the exact moment a system, component, or network service fails until a monitoring system or automated tool successfully identifies and logs that failure.
▷ The MTTD Time Window
MTTD focuses purely on the automation and intelligence built into your monitoring stack. The cycle includes:
Failure Event: The moment the system or component physically or logically fails.
Data Collection: Sensors and logs collect performance data.
Anomaly Identification: The monitoring system processes the data, cross-references baselines, and determines that an anomaly constitutes a fault.
Alert Generation: The system issues the official alert or flags the event in a dashboard.
▷ Calculating the MTTD
MTTD is calculated by averaging the time taken for detection across a set period and number of incidents:

A perfect monitoring system would have an MTTD approaching zero, meaning detection is instantaneous upon failure.
📉 The Critical Business Impact of Low MTTD
Why is achieving an ultra-low MTTD paramount for modern enterprises? It minimizes the impact and cost associated with service disruption.
1. Minimizing the “Impact Window”
The time between the actual failure and its detection is the time when the system is deteriorating without the knowledge of the operations team. This is the period of maximum damage potential. By reducing MTTD, you immediately shrink this perilous impact window, limiting customer churn, lost transactions, and reputational harm.
2. The Starting Line for Incident Response
MTTD is the mandatory prerequisite for all subsequent recovery metrics. The incident lifecycle flows linearly:

If your MTTD is high (e.g., 30 minutes), your best-case total downtime is automatically 30 minutes, even if your MTTA (Acknowledge) and MTTR (Repair) are near-instantaneous. Improving detection speed fundamentally shortens the entire incident chain.
3. Fulfilling Observability Goals
A low MTTD is the ultimate validation of an effective observability strategy, confirming that the system provides sufficient data, intelligence, and correlation to identify exactly what is failing, when it fails, and why.
💡 Strategies for Achieving Ultra-Low MTTD
Achieving an MTTD measured in seconds requires shifting from simple health checks to deep, granular telemetry and proactive intelligence.
1. Leverage Granular, Real-Time Telemetry
Detection relies entirely on the quality and volume of data collected. Low-fidelity data leads to slow or missed detection.
Network Insight: In fiber-optic networks, the performance data provided by Optical Transceivers is vital. High-grade transceivers featuring DDM (Digital Diagnostics Monitoring) capabilities continuously stream metrics such as optical power, temperature, and voltage. When these precise, quantitative data streams are fed into monitoring tools, anomalies are identified instantly, drastically reducing the time between component failure and system alert generation, thus achieving a superior MTTD.
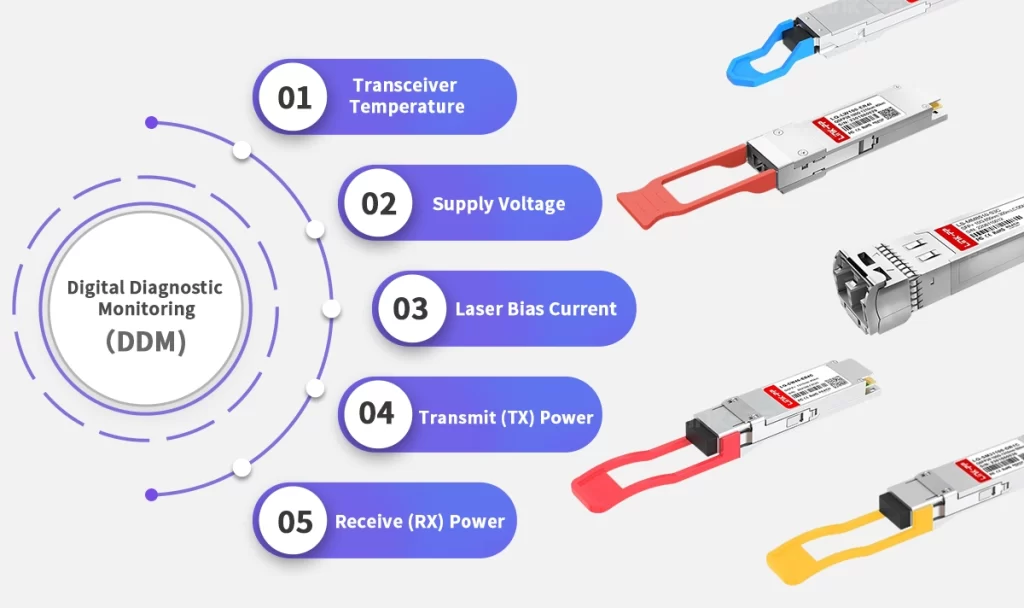
2. Implement Sophisticated Alert Correlation
Avoid monitoring simple thresholds. True detection often relies on correlating multiple, subtle signals across different components. Advanced monitoring tools use AI/ML to detect subtle patterns and anomalies that indicate an impending failure, leading to a faster and more accurate MTTD.
3. Comprehensive Monitoring Coverage
Ensure every critical component, especially those prone to failure or system degradation, is monitored. If a key module—such as an SFP/SFP+—lacks DDM functionality, it creates an immediate blind spot, elevating the potential for a silent failure and a high MTTD.
🌐 Conclusion: Detection as the Ultimate Defense
In the modern digital landscape, the difference between a minor blip and a major outage often hinges on the speed of detection. By treating MTTD as your primary defense metric, you invest in a system that proactively informs you the instant a problem occurs.
By deploying robust monitoring solutions and utilizing components that provide rich, actionable data, such as LINK-PP’s SFP Modules with advanced DDM features, you eliminate blind spots and ensure that your Mean Time to Detect is always minimized, providing the essential starting point for rapid recovery and maximum availability.
🔗 Related Products for Precise Network Detection
Maximize your observability and minimize your MTTD with DDM-enabled optics.
Explore LINK-PP’s range of high-performance SFP and SFP+ Optical Transceivers, engineered with Digital Diagnostics Monitoring to provide the instant, reliable data necessary for ultra-low MTTD.




